We have worked on various projects towards obtaining a concrete, grounded, semantic understanding of 3D environments. What do we mean by understanding of 3D environments? Our key insight is viewing real environments as spaces in which human actions take place. Indoor spaces in particular are canvases that are designed by people to facilitate everyday human actions. As people spend the vast majority of their time indoors, the focus of visual computing research on understanding of interiors is increasingly important.
We seek to answer a number of research questions:
- How do people interact with environments in the real world? What actions can they take? Where can they perform certain actions? How are objects arranged in an environment to enable actions?
- How do environments evolve and change over time? How do human actions change an environment?
- Can we learn a unified model of environments from data? How do we encode common knowledge about environments in this model?
- How do people name objects in real scenes? How are these names dependent on the appearance, functionality, and context?
- What are good representations for 3D scenes? What features of 3D scene representations for real environments are salient for people?
Scene understanding and representation
Underlying any attempt at understanding environments, we must consider how environments are to be represented. What properties of a representation are necessary to allow us to generate new environments and allow users to easily manipulate and interact with a 3D virtual environment?
We believe that a structured and relationship-based representation enables easy manipulation of scenes. Thus, in many of our projects, we represent scenes as graphs that encode objects and their semantic relationships. In Characterizing Structural Relationships in Scenes using Graph Kernels (pdf), we use graphs to represent scenes and define a similarity function between the graphs to enable retrieval of similar scenes. The representation of a scene as semantic graph is used in many of the projects described below.
Human-centric understanding of 3D environments
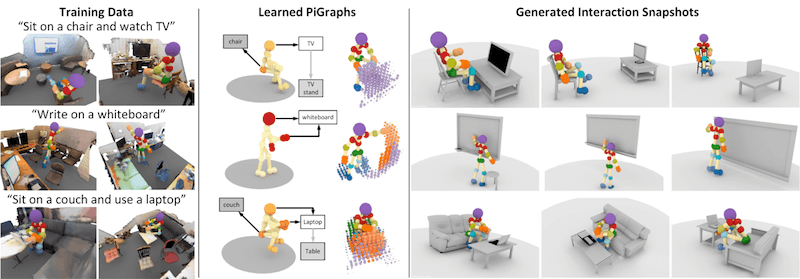
A key to understanding real world environments is to examine how people interact with their surroundings and how the environment is structured and designed to support human activities. This is especially true of indoor environments, where architects, builders, and designers have specifically created spaces for us to live and work in. We view environments as spaces for action.
- SceneGrok (webpage) asks the question where can a person do action X? in a given 3D scene.
- Activity based scene synthesis (webpage) shows that knowledge of human activities be used to help us arrange objects into more plausible 3D scenes.
- PiGraphs (webpage) asks the question what does a static snapshot of a interaction such as 'watching TV' look like? In this project we create a system that generates both the pose of the person and arranges objects with respect to the pose to demonstrate a particular interaction.
Data-based 3D scene synthesis

Understanding can be demostrated by building a model from which examples can be generated. For us, that means that building a generative model of environments that we can use to create new environments. As it can be difficult to specify by hand the different rules that give rise to indoor environments, we believe it is important to learn these models from data. To that end, we have a series of projects that aim to learn common sense priors on the arrangement of objects and use those priors to synthesize new scenes or to make changes to existing scenes.
- Example-based 3D scene synthesis (webpage) Content creation is a time-consuming and challenging task. In this project, we use object statistics and arrangement priors learned from a dataset of synthetic scenes to generate similar yet novel scenes given a few examples.
- Activity-based 3D scene synthesis (webpage) As indoor environments are spaces for action, how objects are arranged is often a consequence of what actitivies the environment is designed to support. In this project, we use knowledge of human actions to improve arrangement of the objects into plausible 3D scenes.
- Text to 3D scene generation (webpage, demo) A natural way for people to communicate what they want is via language. In this project, we synthesize novel scenes based on natural language descriptions such as "a living room with a red couch".
- Scene editing (paper, demo) Designing 3D scenes with current interfaces is a challenging and effortful task. In this project, we seek to facilitate scene editing by allowing users to select an area where they would like to position an object, and then using priors of what objects typically occur at that location, to suggest and automatically place objects at an appropriate orientation and scale.
Learning from 3D environments
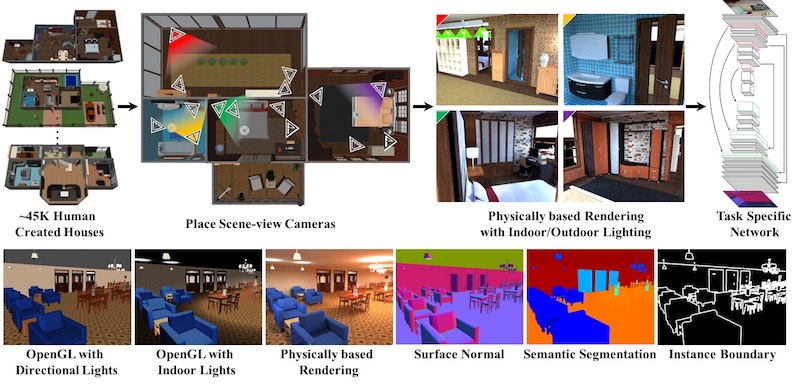
Since a big focus of our research is in leveraging 3D data for learning, we have helped to create several large semantically annotated 3D datasets (see datasets for more details). We want to leverage virtualizations of real 3D environments to create improved synthetic environments, and use existing 3D data to improve virtualizations of real environments. We are also interested in exploring whether synthetic data can be used to generate training data for scene understanding.
- Semantic scene completion (webpage) From a single depth image, can we leverage synthetic data to produce a 3D voxelization of the space with predicted semantic labels for both observed and occluded regions?
- Physically-based rendering (webpage) Can we utilize physically-based renderings of synthetic 3D scenes as training data for improving performance on common vision tasks such as surface normal estimation and semantic segmentation?
- Learning where to look (pdf) Training data generation for vision tasks that rely on renderings from a single viewpoint, requires a strategy for determining viewpoints that are appropriate. In this project, we generate viewpoints for a 3D space that semantically match those found in a reference set of images.
Indoor simulation

We believe that true understanding goes beyond passive recognition. An agent must be able to interact with objects in the environment and to observe changes. To enable understanding of environments via interaction, we have developed a multimodal indoor simulator platform:
- MINOS: Multimodal Indoor Simulator (webpage)
We hope that this indoor simulation platform can be used by researchers in vision, robotics, natural language processing, and machine learning to investigate a variety of open research questions revolving around intelligent behavior of embodied agents in 3D interior environments.